Let's say we start with a brand-new neuronal network that aims to estimate the price of a house solely based just on the size of that house. A perceptron with one input, one output, and one weight.
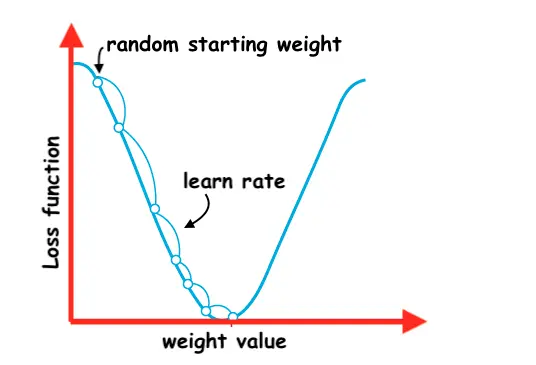
Initially, the untrained network will start from a small random weight value.
At this stage, we will ask the network to make some price predictions:
const prediction1 = model.predict(size1)
const prediction2 = model.predict(size2)
// ...
const predictionN = model.predict(sizeN)Given that the network is untrained the price predictions will be way off from the real prices.
The loss function is the discrepancy between the prediction made by our model vs the real price. There are a few different ways to measure the loss function (eq: mean squared error).
The scope of training a neuronal network is to find the right value for the weight so that the loss function is as small as possible.
We can draw a 2D graph where we have on one axis the value of the loss function and on another axis the weight value.
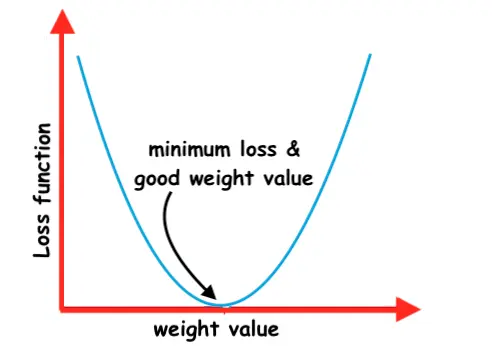
The gradient descent algorithm is used to minimize the loss function of a neuronal network.
The main idea is to move in the direction of the steepest descent of the loss function aiming to reach the minimum loss.
The size of the steps we take toward minimizing the loss function is called the learning rate.
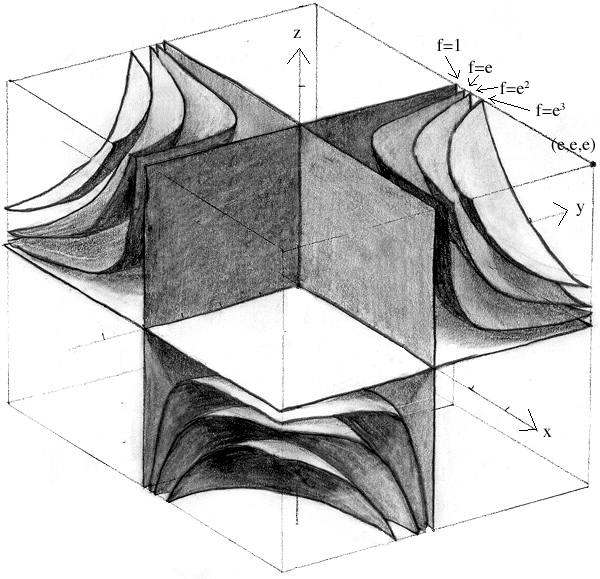
But what if our model would have had 2 weights? Well in that case we will have a 3D graph.
{kind=link}
Starting from 3 weights and above the graphs will become harder to visualize, eq a 4D graph, but the same principles will apply.
{kind=link}
📖 50 Javascript, React and NextJs Projects
Learn by doing with this FREE ebook! Not sure what to build? Dive in with 50 projects with project briefs and wireframes! Choose from 8 project categories and get started right away.
📖 50 Javascript, React and NextJs Projects
Learn by doing with this FREE ebook! Not sure what to build? Dive in with 50 projects with project briefs and wireframes! Choose from 8 project categories and get started right away.